현재 문제 01부터 39까지만 한국어로 제공되고 있습니다. 40번부터 99번은 번역이 완료되는대로 공개 예정입니다.

제1장: 준비 운동
텍스트나 문자열을 다루는 기초 문제를 통하여, 프로그래밍 연습을 하며 중요한 기초를 복습합니다.

제2장: UNIX 명령어
연구나 데이터 분석에 편리하게 사용 가능한 UNIX 명령어들을 소개합니다. 이를 직접 구현해보면서 프로그래밍 능력을 향상시키고, 기존의 툴이 있는 생태계를 경험합니다.

제3장: 정규 표현식
Wikipedia의 페이지를 대상으로 정규 표현식을 이용, 여러가지 정보와 지식을 추출하는 기법을 연습합니다.
제4장:형태소 분석
소설 “이상한 나라의 앨리스”를 데이터로 이용, 형태소 분석기로 분석하여 소설 내용에 대한 통계를 구합니다.
제5장: 구문 분석
소설 “이상한 나라의 앨리스”를 데이터로 이용, 구문 분석기를 이용한 구문 트리 사용법을 익합니다.

제6장: 기계 학습
기계 학습을 이용하여 문서 분류 모델을 학습하여 봅니다. 추가적으로, 기계 학습 모델의 평가 기법을 다루어 봅니다.

제7장: 단어 벡터
단어의 유사도 계산과 단어 유추 등을 통하여 단어 벡터 사용법을 익힙니다. 추가적으로, 클러스터링과 단어 벡터의 시각화 또한 연습합니다.
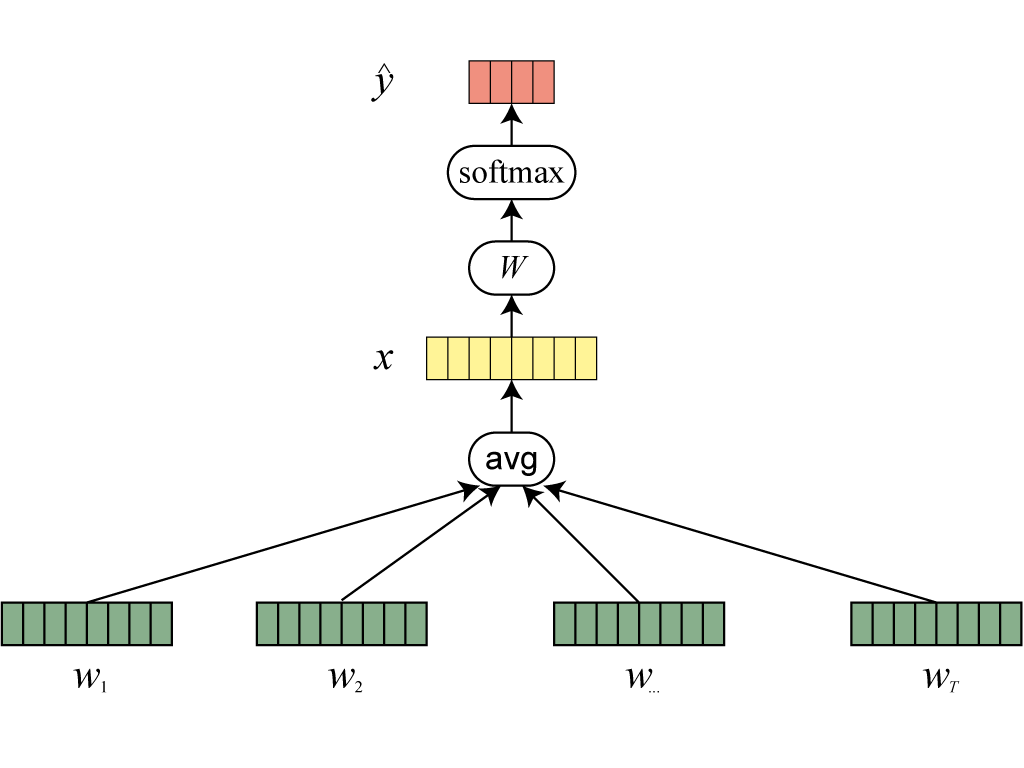
제8장: 신경망
딥러닝 프레임워크 사용법을 배우고, 신경망을 이용한 문서 분류 모델을 구현해봅니다.
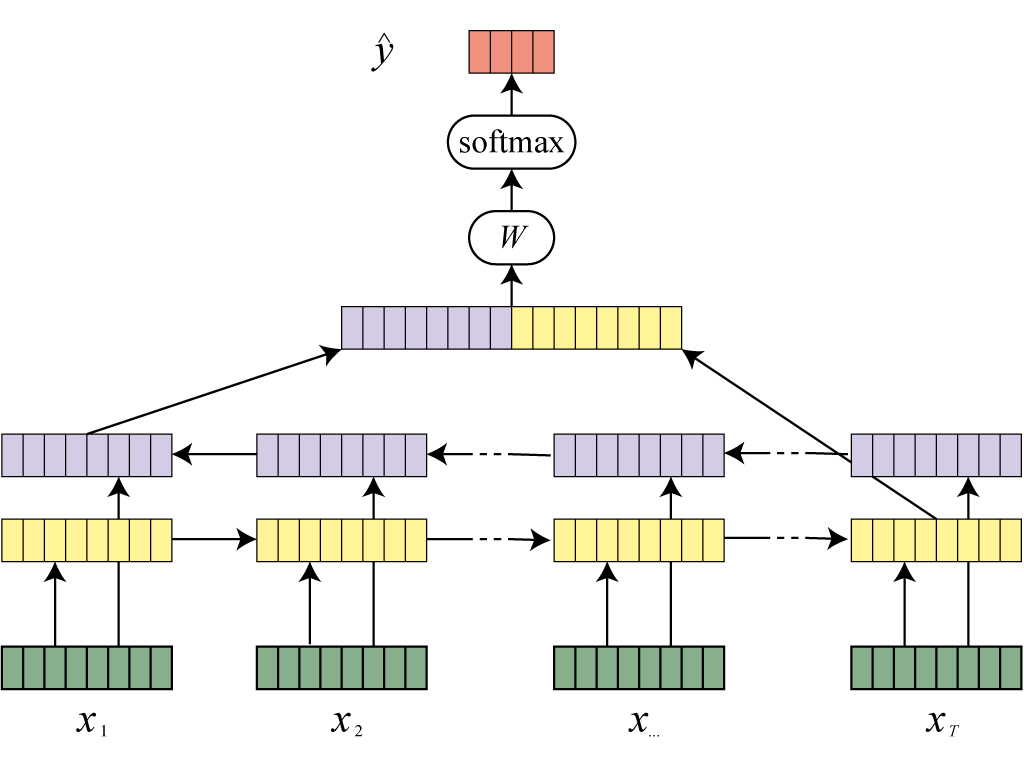
제9장: RNN과 CNN
딥러닝 프레임워크를 이용하여, 재귀 신경망과 (RNN) 합성곱 신경망을 (CNN) 구현해봅니다.
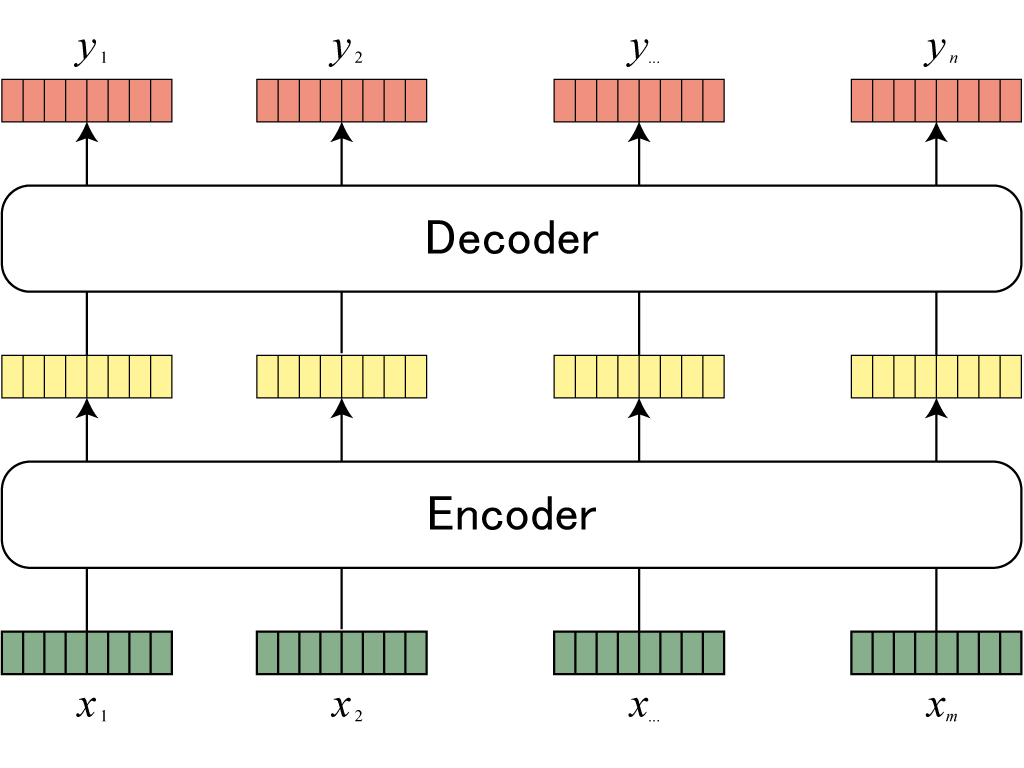
제10장: 기계 번역
기존의 툴을 이용하여 신경망 기반 기계 번역 모델을 구현해봅니다.