実行環境#
言語処理100本ノック 2025を始めるにはプログラミング環境が必要です。また、第8章から第10章までの問題の一部では、GPUなどの深層学習向けアクセラレータが必要になります。深層学習向けのプログラミング環境を整備するには、高度な知識やスキルが必要になりますので、特段の理由が無ければGoogle ColaboratoryやSageMaker Studio Labなどのクラウド上のJupyter実行環境を活用することをお勧めします。
Google Colaboratory#
各章のページ右上のロケット(🚀)のアイコンをクリックし、Colabを選ぶと、Google Colaboratory上でその章の問題を(Jupyter Notebookとして)開くことができます。

あとは、コードセルを挿入してコーディングを行い、プログラムを実行しながら学習を進めましょう。Google Colaboratoryの基本的な使い方は、他のウェブサイト等を参考にしてください。Python早見帳にもGoogle Colaboratoryの使い方がまとめられています。
以降では、特に重要な事柄を説明します。
APIキーの管理#
言語処理100本ノックの5章で大規模言語モデルの有料API(例えばOpenAIのGPT-4シリーズのAPI)を利用する場合、APIキーが必要になります。 このAPIキーが漏洩してしまうと、他人が勝手に有料のAPIを使い、その利用料があなたに請求されることになります。 Google Colaboratoryのコードセル中にAPIキーをべた書きしていると、Notebookを他人と共有した時にAPIキーが漏洩する恐れがあります。 また、GitHubなどのレポジトリで管理しているソースコードの中にAPIキーを書いてしまうと、やはりAPIキーの漏洩につながります(特にパブリックレポジトリでは危険です)。 したがって、コード中にAPIキーを書かないという鉄則を身に付けておくことが大切です。
Google Colaboratoryには、APIキーのような秘密の文字列を管理する機能があります。左側のツールバーから鍵(🔑)のアイコンをクリックすると、キーとその値を管理する画面が現れます。ここで、キーの名前を適当に決めて「名前」欄に、キーの内容を「値」欄に入力し、「ノートブックからのアクセス」にチェックを入れます。すると、ここに登録したAPIキー(値)をコードの実行時に取得できます。
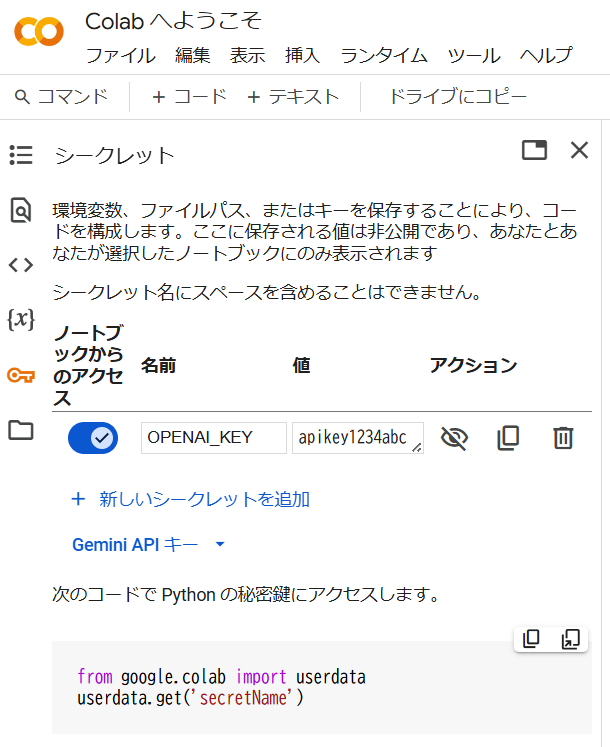
例えば、OPENAI_KEYとしてapikey1234abcを登録した場合、以下のコードを実行すると変数api_keyに文字列"apikey1234abc"が得られます。
from google.colab import userdata
api_key = userdata.get('OPENAI_KEY')
この変数を使ってOpenAIのライブラリにAPIキーを渡せば、コード中にAPIキーを書かずに済みます。このような秘密の文字列の管理は、第9章や第10章でHuggingFaceのアクセストークンやWandBのAPIキーの管理でも重宝します。
ランタイムの選択#
自然言語処理の研究や開発では、数時間から数日、もしくは数か月かかるプログラムを動かすことがありますが、言語処理100本ノックのすべての問題は、Google Colaboratory上の計算資源で実行できるように調整してあります。ほとんどの問題のプログラムはすぐに実行が終了すると思いますが、中には実行に数秒から1分近くかかる問題もあります。また、GPU等のハードウェアを用いても、数分から1時間以上かかる問題(モデルの学習など)もあります。
問題77-79と問題87-89を除き、第1章から第9章まではCPUランタイムで実行できます。以下はCPUで実行することが想定されている問題のうち、実行に比較的時間がかかる問題です。参考までに、問題作成時の検証実験における実行時間を示します。
問題73: 2分10秒(1エポックあたりの実行時間、単語埋め込みの次元数は300)
問題76: 18秒(1エポックあたりの実行時間、単語埋め込みの次元数は300、バッチサイズは8)
第8章の問題のうち、GPUで実行することが想定されている問題の実行時間をT4 GPUで測定しました。
問題77: 21秒(1エポックあたりの実行時間、単語埋め込みの次元数は300、バッチサイズは8)
問題78: 1分36秒(1エポックあたりの実行時間、単語埋め込みの次元数は300、単語埋め込みも更新、バッチサイズは8)
問題79: 1分48秒(1エポックあたりの実行時間、単語埋め込みの次元数は300、単語埋め込みも更新、ラベル予測の直前に次元数8の隠れ層とReLUを追加、バッチサイズは8)
問題79: 1分59秒(1エポックあたりの実行時間、単語埋め込みの次元数は300、単語埋め込みも更新、次元数が50の2層の畳み込みニューラルネットワーク (CNN) を追加、バッチサイズは8)
問題79: 2分16秒(1エポックあたりの実行時間、単語埋め込みの次元数は300、単語埋め込みも更新、次元数が50の2層の再帰型ニューラルネットワーク (RNN) を追加、バッチサイズは8)
第9章の問題のうち、問題87と問題89はGPUで実行することが推奨されます。問題88の実行にGPUは必須ではありませんが、問題87で学習したモデルがGPUランタイム上にあるため、問題88もGPUで実行することになります。BERTモデルとしてModernBERT-baseを用いた場合の実行時間をT4 GPUで計測しました。
問題87: 12分7秒(1エポックあたりの実行時間、デフォルトのラベル予測アーキテクチャを採用、BERTのモデルパラメータも更新、バッチサイズは32)
問題89: 12分6秒(1エポックあたりの実行時間、最終層のトークン埋め込みに対して最大値プーリングを適用し、50次元の隠れ層とReLU、ドロップアウトを通してからラベルを予測、BERTのモデルパラメータも更新、バッチサイズは32)
参考までに、問題87をCPU上で動作させると、1エポックあたりの実行時間が約29時間と見積もられました。BERTのパラメータを更新しないようにすることで、CPU上で学習することは不可能ではないと思いますが、事前学習モデルのファインチューニングにはGPUなどのハードウェアが当然のように用いられますので、GPUの利用に慣れておいた方がよいと思います。
第10章の問題は、すべてGPUランタイムで実行することが推奨されます。用いる事前学習済み言語モデルによって、必要な計算資源が大きく異なりますが、ここではMeta Llama 3.2 1B Instruct (meta-llama/Llama-3.2-1B-Instruct) を例に説明します。このモデルのダウンロードに時間がかかりますが、問題95までのプログラムの実行はすぐに終わります。 問題96以降の実行時間をA100 GPUランタイム(有料)上で計測しました。
問題96: 10分34秒(最大で32トークンを生成、バッチサイズは1)
問題97: 19分36秒(1エポックあたりの実行時間、標準的なラベル予測アーキテクチャを採用、モデルのパラメータも更新、学習時に26.4GBのGPUメモリを消費)
問題98: 7分14秒(1エポックあたりの実行時間、ランク16のLoRAチューニング、学習時に3.5GBのGPUメモリを消費)
問題99: 17分17秒(1エポックあたりの実行時間、DPO、ランク16のLoRAチューニング、学習時に16.4GBのGPUメモリを消費)
なお、第10章のプログラムを動作させるときに必要となる計算資源は、事前学習済み言語モデルのパラメータ数、学習に用いるライブラリ・アルゴリズムによって大きく異なります。
単語ベクトルの読み込み#
事前学習済みの単語ベクトルを扱うとき、gensimがよく用いられると思います。
gensimはGoogle Colaboratoryにインストールされていないので、pip install gensimをコマンドとして実行し、手動でインストールする必要があります。ところが、gensimはNumPy 2.xと互換性が無いため、gensimをインストールするとNumPyのバージョンが1.xにダウングレードされます。このとき、Google Colaboratoryのランタイムを再起動する必要があるようなのですが、そのような指示が表示されません。gensimのインストールが完了したら、Google Colaboratoryのメニューバーから「ランタイム」→「セッションを再起動する」をクリックし、ランタイムを再起動してください。ランタイムを再起動した後に、pip install gensimを再実行する必要はありません。
生成AIによるコード生成・補完#
Google Colaboratoryには生成AI (Gemini) によるコード生成やコード補完の機能が備わっています。 これを上手に活用することで、コーディング作業を効率化できますが、処理をプログラムに落とし込む方法を考えずにコードが書けてしまうので、コーディングスキルが身に付かないという欠点があります。 コーディングの方針を頭の中で考える、ライブラリの利用方法をウェブで調べる、英語のドキュメントを読む、ややこしいテンソルの中身を理解するなど、言語処理100本ノックの問題を解くときに同時に鍛えられるスキルがありますので、最初のうちは生成AIを使わずに、自力でコードを書いた方がよいと思います。 生成AIの機能をオフにするには、設定(⚙)アイコンをクリックし、「AIアシスタント」タブで「AIによるコード補完を表示」のチェックを外してください。
GitHubレポジトリでの解答の管理#
大学や会社の同期と一緒に言語処理100本ノックを解き、お互いのコードを解説・理解・批評するような勉強会を開催すると、学習効果が高まります。 勉強会では、GitHubのプライベートレポジトリを作成し、参加者のコードを共有するという運用をとることが考えられます。 その場合、Google ColaboratoryからレポジトリのJupyter Notebookを直接読み書きする機能を活用すると便利です。 「ファイル」→「ノートブックを開く」のダイアログで、「GitHub」タブをクリックすると、プライベートレポジトリも含めてGitHubのレポジトリ上にあるJupyter Notebook (*.ipynb) を直接開くことができます。 Google Colaboratory上でNotebookの内容を編集したら、「ファイル」→「保存」でGitHubのレポジトリに変更をコミットできます。 この機能は大変便利ですが、Notebookの自動保存ができないため、ブラウザがクラッシュするとNotebookの変更点が失われます。